
In a stateful streaming application the state of an application is one of the most important part. In Apache Flink we have the possibility to kind of backup the state with a so called savepointing mechanism. From these savepoints you as a developer or operations manager are able to stop-and-resume, fork, or update your Flink jobs (more to read about savepoints in the docs). So it’s a great possibility to try out different implementations of a fork for a Flink application.
In one of my previous project we have used Enterpise Ververica Platform (VVP) to manage all Flink jobs. From VVP UI its quite easy to trigger a savepoint every now and then. But if your requirement is to trigger a savepoint on regular basis then this approach via the UI is obviously a hassle. At a client project the savepoints were triggered via the UI button on daily basis, so clearly the target was to automate this tedious job.
Thankfully the VVP has also exposed a REST-API endpoint to trigger a savepoint.
But unfortunately one has to pass the deploymentId into the request body, which has been created and assigned to the flink jobs internally by the VVP. The issue we were facing were the following:
a) cryptical (UUID), in the sense if you define it somewhere like in a Kubernetes cronjob you aren’t able to figure out which job you are savepointing if you have multiple flink jobs runnnig and
b) it could potentially be changed by VVPs internal logic.
How to trigger savepoints in Ververica Platform
So the goal was to have a solution where you can pass just the name of the Flink application. And not only one application rather a list of flink applications version controlled that needs to be savepointed on regular basis.
Since the Flink jobs were running in Kubernetes it was kind of obvious to create a Helm Chart were you pass in the name of the applications into well known values.yaml file.
So the interesting part was that the application logic (script) of translating the name of the application to a deploymentId was done via kubernetes API calls. This was archiveable because the VVP put both information (deploymentId & deploymentName) into the labels of the launched pods.
sequenceDiagram
Script->>+Kubernetes-API: get pods with the label
Kubernetes-API->>+Script: returns pods and filter with jq
Script->>VVP-Service: take a savepoint for a specific deploymentId
The Helm Chart is triggering the savepointing mechanism, using the CronJob API in Kubernetes so one has to define also the interval of the cronjob in the format like for e.g. 0 1 * * * (daily at 1AM).
side note: taking savepoints of a Flink job at low inbound events would be preferable due to extra load for the jobmanager to manage.
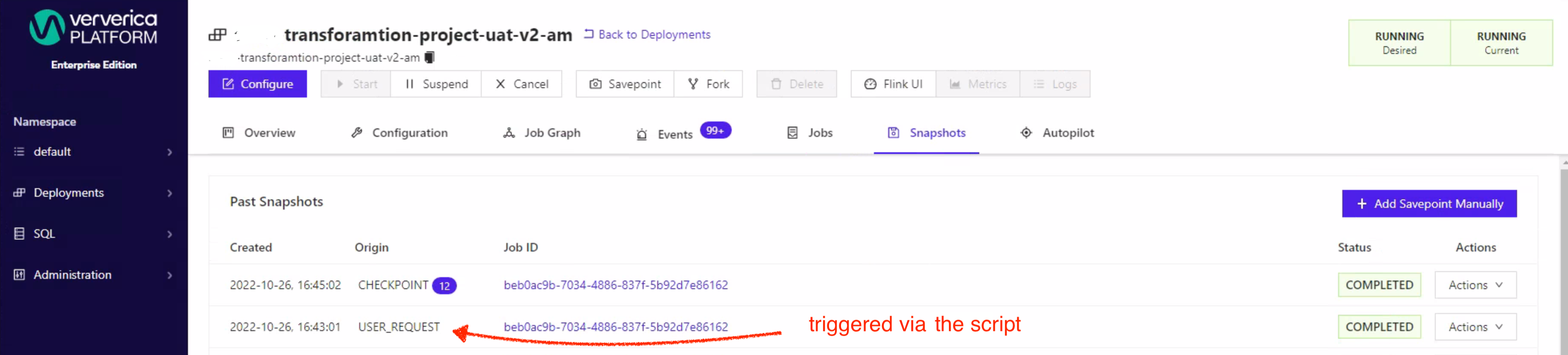
The triggered savepoints can be observed in the UI under the Snapshots tab as a type USER_REQUEST from where the user is able to take further actions with the taken savepoint.
The solution shown in this blogpost wouldn’t be necessary if Ververica Platform would integrate this feature of taking savepoints on intervals via UI. This would make this solution then obsolete.
Conclusion
In this blogpost I’ve shown how to take savepoints on regular intervals of an Apache Flink stateful application launched by Ververica Platform within Kubernetes. The same approach can be adjusted for Flink application if you are not using VVP. The jobmanager itself is exposing this kind possibility to take savepoints via the REST-API.