Originally published at codecentrics blog
“ETL with Kafka” is a catchy phrase that I purposely chose for this post instead of a more precise title like “Building a data pipeline with Kafka Connect”.
TLDR
You don’t need to write any code for pushing data into Kafka, instead just choose your connector and start the job with your necessary configurations. And it’s absolutely Open Source!
Kafka Connect
Kafka
Before getting into the Kafka Connect framework, let us briefly sum up what Apache Kafka is in couple of lines. Apache Kafka was built at LinkedIn to meet the requirements that message brokers already existing in the market did not meet – requirements such as scalable, distributed, resilient with low latency and high throughput. Currently, i.e. 2018, LinkedIn is processing about 1.8 petabytes of data per day through Kafka. Kafka offers a programmable interface (API) for a lot of languages to produce and consume data.
Kafka Connect
Kafka Connect has been built into Apache Kafka since version 0.9 (11/2015), although the idea had been in existence before this release, but as a project named Copycat. Kafka Connect is basically a framework around Kafka to get data from different sources in and out of Kafka (sinks) into other systems e.g. Cassandra with automatic offset management, where as a user of the connector you don’t need to worry about this, but rely on the developer of the connector.

Besides that, in discussions I have often come across people who were thinking that Kafka Connect was part of the Confluent Enterprise and not a part of Open Source Kafka. To my surprise, I have even heard it from a long-term Kafka developer. That confusion might be due to the fact that if you google the term Kafka Connect, the first few pages on Google are by Confluent and the list of certified connectors.
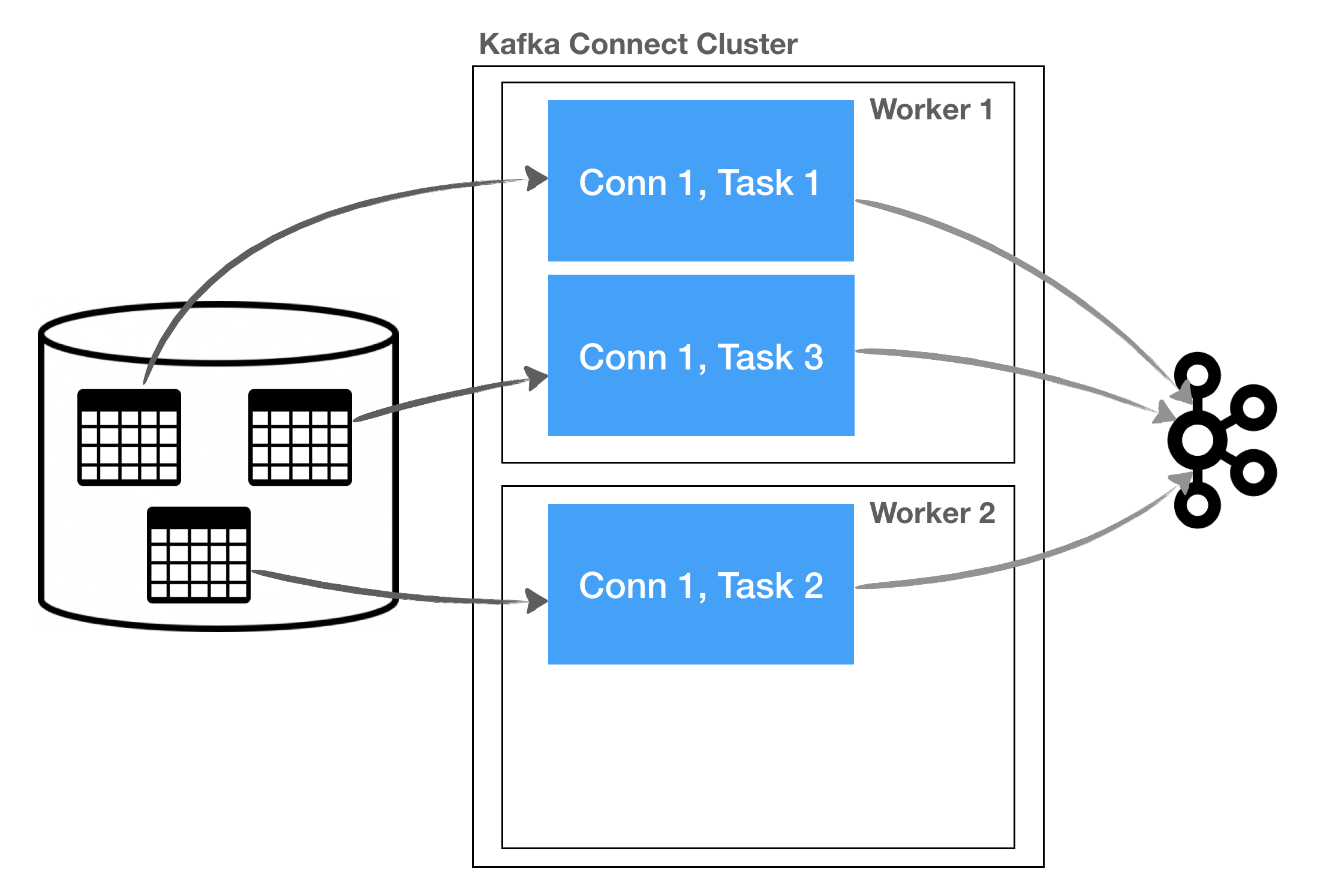
Kafka Connect has basically three main components that need to be understood for a deeper understanding of the framework.
Connectors are, in a way, the “brain” that determine how many tasks will run with the configurations and how the work is divided between these tasks. For example, the JDBC connector can decide to parallelize the process to consume data from a database (see figure 2).
Tasks contain the main logic of getting the data into Kafka from external systems by connecting e.g. to a database (Source Task) or consuming data from Kafka and pushing it to external systems (Sink Task).
Workers are the part that abstracts away from the connectors and tasks in order to provide a REST API (main interaction), reliability, high availability, scaling, and load balancing.
Standalone
Kafka connect can be started in two different modes. The first mode is called standalone and should be used only in development because offsets are being maintained on the file system. This would be really bad if you were running this mode in production and your machine was unavialable. This could cause the loss of the state, which means the offset is lost and you as a develeoper don’t know how much data has been processed.
# connnect-standalone.properties
offset.storage.file.filename=/tmp/connect.offsets
Distributed
The second mode is called distributed. There, the configuration, state and status are stored in Kafka itself in different topics which benefit from all Kafka characteristics such as resilience and scalability. Workers can start on different machines and the group.id attribute in the .properties file will eventually form the Kafka Connect Cluster which can be scaled up or down.
# connnect-distributed.properties
group.id=connect-cluster
config.storage.topic=connect-configs
offset.storage.topic=connect-offsets
status.storage.topic=connect-status
So let’s look in the content of the pretty self-explanatory topic use in the configuration file:
// TOPIC => connect-configs
{"properties": {
"connector.class":"c.e.t.k.c.twitter.TwitterSourceConnector",
"twitter.token":"XXXX",
"tasks.max":"1",
"track.terms":"frankfurt",
"task.class":"c.e.t.k.c.twitter.TwitterSourceTask",
"twitter.secret":"XXX",
"name":"twitter-source",
"topic": "twitter",
"twitter.consumersecret":"XXXXXX",
"twitter.consumerkey":"XXXXX"
}}
// response
{"tasks":1}
{"state":"STARTED"}
// TOPIC => connect-offsets
{"tweetId":968476484095610880}
{"tweetId":968476527108263936}
// TOPIC => connect-status
{"state":"RUNNING","trace":null,"worker_id":"connect:8083", "generation":2}
{"state":"UNASSIGNED","trace":null,"worker_id":"connect:8083", "generation":2}
{"state":"RUNNING","trace":null,"worker_id":"connect:8083", "generation":3}
The output shown here of the messages are just the values, the key of the message is used to identify the different connectors.
Interaction pattern
There is also a different interaction pattern normally between the standalone and distributed mode – in a non-production environment where you just want to test out a connector, for example, and you want to set manually the offset of your choice. You can start the standalone mode with passing in the sink or source connector that you want to use, e.g. bin/kafka-connect config/connect-standalone.properties config/connect-file-source.properties config/other-connector.properties.
On the other hand, you can start the Kafka Connect worker in the distributed mode with the following command: bin/kafka-connect config/connect-distributed.properties. After that, you can list all available connectors, start, change configurations on the fly, restart, pause and remove connectors via the exposed REST API of the framework. A full list of supported endpoints can be found in the offical Kafka Connect documentation.
Example
So let’s have a closer look at an example of a running data pipeline where we are getting some real time data from Twitter and using the kafka-console-consumer to consume and inspect the data.

Here is the complete example shown in the terminal recording: Github repository. You can download and play around with the example project.
Conclusion
In this blog post, we covered the high-level components that are the building blocks of the Kafka Connect framework. The latter is a part of the Apache Kafka Open Source version that allows data engineers or business departments to move data from one system to another without writing any code via Apache Kafka’s great characteristics, of which we barely scratched the surface in this post. So happy connecting…